在 Linux 服务器上使用 GPU 跑深度学习的模型很正常不过。如果我们想用 Docker 实现同样的需求,就需要做些额外的工作。本质上就是我们要在容器里能看到并且使用宿主机上的显卡。 在这篇文章里我们就介绍一下 Docker 使用 GPU 的环境搭建。
Nvidia 驱动
某些命令以 Ubuntu 作为示例。 首先宿主机上必现安装 Nvidia 驱动。
这里推荐从 Nvidia 官网下载脚本安装,安装和卸载都比较方便并且适用于任何 Linux 发行版,包括 CentOS,Ubuntu 等。 NVIDIA Telsa GPU 的 Linux 驱动在安装过程中需要编译 kernel module,系统需提前安装 gcc 和编译 Linux Kernel Module 所依赖的包,例如 kernel-devel-$(uname -r) 等。
安装 gcc 和 kernel-dev
1 | $ sudo apt install gcc kernel-dev -y |
安装 Nvidia 驱动
-
选择对应操作系统和安装包,并单击 [SEARCH] 搜寻驱动,选择要下载的驱动版本
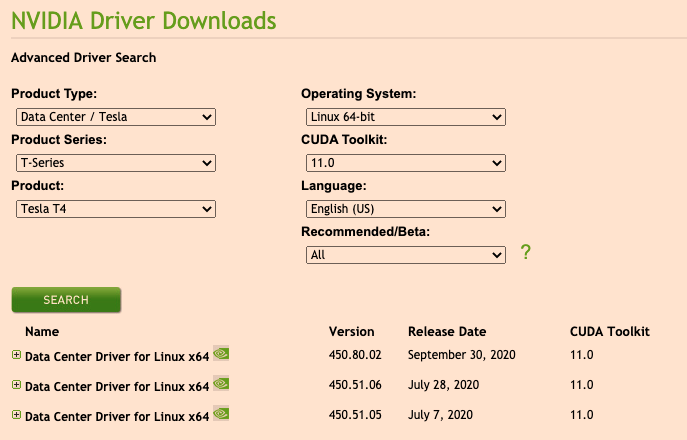
- 在宿主机上下载并执行对应版本安装脚本
1 | $ wget https://www.nvidia.com/content/DriverDownload-March2009/confirmation.php?url=/tesla/450.80.02/NVIDIA-Linux-x86_64-450.80.02.run&lang=us&type=Tesla |
- 验证
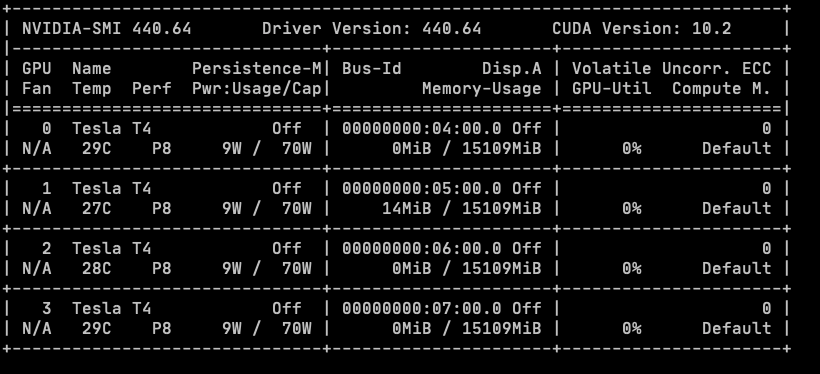
使用 nvidia-smi 命令验证是否安装成功,如果输出类似下图则驱动安装成功。
CUDA 驱动
CUDA(Compute Unified Device Architecture)是显卡厂商 NVIDIA 推出的运算平台。CUDA™是一种由 NVIDIA 推出的通用并行计算架构,该架构使 GPU 能够解决复杂的计算问题。它包含了 CUDA 指令集架构(ISA)以及 GPU 内部的并行计算引擎。 这里安装的方式和显卡驱动安装类似。
- 访问官网下载对应版本安装包,https://developer.nvidia.com/cuda-toolkit-archive

- 配置环境变量
1 | $ echo 'export PATH=/usr/local/cuda/bin:$PATH' | sudo tee /etc/profile.d/cuda.sh |
nvidia-docker2
Docker 的安装这里就不展开了,具体查看官方文档非常详细。
这里我们就直接介绍安装 nvidia-docker2.
既然叫 nvidia-docker2 就有 nvidia-docker1 就是它的 1.0 版本目前已经废弃了,所以注意不要装错。
这里先简单说一下 nvidia-docker2 的原理,nvidia-docker2 的依赖由下几部分组成.
- libnvidia-container
- nvidia-container-toolkit
- nvidia-container-runtime
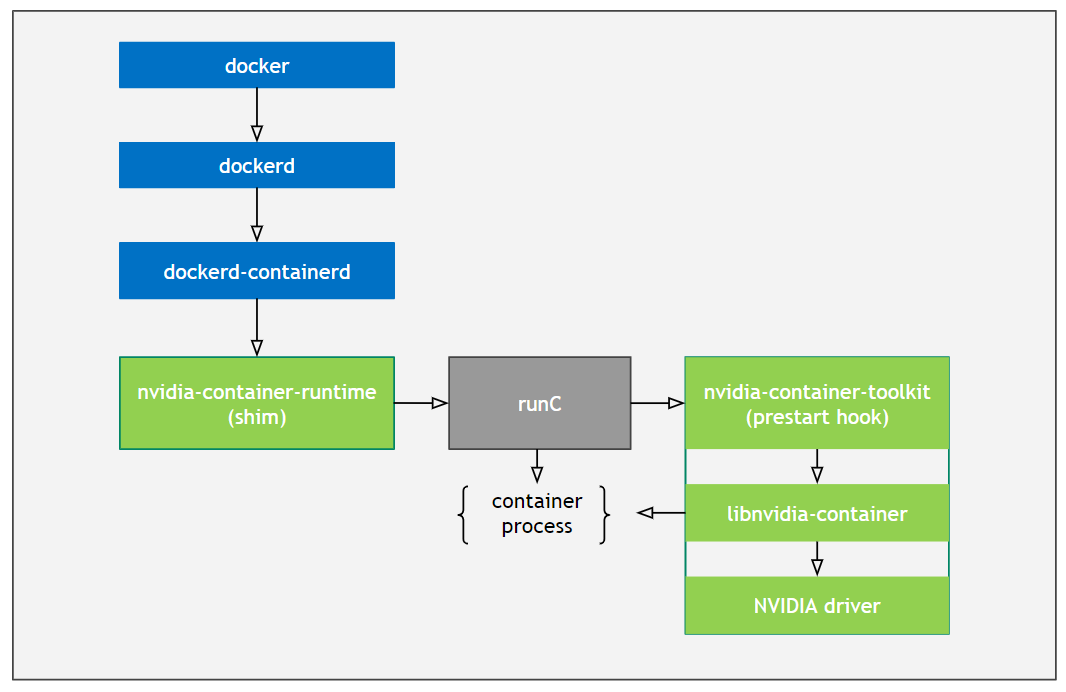
nvidia-container-runtime 是在 runc 基础上多实现了 nvidia-container-runime-hook (现在叫 nvidia-container-toolkit),该 hook 是在容器启动后(Namespace已创建完成),容器自定义命令(Entrypoint)启动前执行。当检测到 NVIDIA_VISIBLE_DEVICES 环境变量时,会调用 libnvidia-container 挂载 GPU Device 和 CUDA Driver。如果没有检测到 NVIDIA_VISIBLE_DEVICES 就会执行默认的 runc。
下面分两步安装
- 设置 repository 和 GPG key
1 | $ distribution=$(. /etc/os-release;echo $ID$VERSION_ID) |
- 安装
1 | $ sudo apt-get update |
- 验证
执行以下命令:
1 | $ docker run --rm --gpus all nvidia/cuda:10.2-base nvidia-smi |
如果输出跟直接在宿主机上执行 nvidia-smi 一致则说明安装成功。 如果跑的深度学习模型使用的是 tensorflow 可以在容器里执行:
1 | import tensorflow as tf |
如果输出了宿主机上的 Nvidia 显卡数量,则模型能使用到显卡加速。 如果使用的是 pytorch 可以在容器里执行:
1 | import torch |
如果输出 True 证明环境也成功了,可以使用显卡。
- 使用示例
- 使用所有显卡
1 | $ docker run --rm --gpus all nvidia/cuda nvidia-smi |
- 指明使用哪几张卡
1 | $ docker run --gpus '"device=1,2"' nvidia/cuda nvidia-smi |
到这里在 Docker 下使用 Nvidia 显卡加速计算的基础环境搭建就介绍完了。后续我们可以继续研究一下 K8S 下调度 GPU 的实现。
本文转载自:「lxkaka」,原文:https://lxkaka.wang/docker-nvidia/,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。