前言
主流的 ELK (Elasticsearch, Logstash, Kibana) 目前已经转变为 EFK (Elasticsearch, Filebeat or Fluentd, Kibana) 比较重,对于容器云的日志方案业内也普遍推荐采用 Fluentd,我们一起来看下从 ELK 到 EFK 发生了哪些变化,与此同时我也推荐大家了解下 Grafana Loki
ELK 和 EFK 概述
随着现在各种软件系统的复杂度越来越高,特别是部署到云上之后,再想登录各个节点上查看各个模块的 log,基本是不可行了。因为不仅效率低下,而且有时由于安全性,不可能让工程师直接访问各个物理节点。而且现在大规模的软件系统基本都采用集群的部署方式,意味着对每个 service,会启动多个完全一样的 POD 对外提供服务,每个 container 都会产生自己的 log,仅从产生的 log 来看,你根本不知道是哪个 POD 产生的,这样对查看分布式的日志更加困难。
所以在云时代,需要一个收集并分析 log 的解决方案。首先需要将分布在各个角落的 log 收集到一个集中的地方,方便查看。收集了之后,还可以进行各种统计分析,甚至用流行的大数据或 maching learning 的方法进行分析。当然,对于传统的软件部署方式,也需要这样的 log 的解决方案,不过本文主要从云的角度来介绍。
ELK 就是这样的解决方案,而且基本就是事实上的标准。ELK 是三个开源项目的首字母缩写,如下:
E: Elasticsearch
L: Logstash
K: Kibana
Logstash 的主要作用是收集分布在各处的 log 并进行处理;Elasticsearch 则是一个集中存储 log 的地方,更重要的是它是一个全文检索以及分析的引擎,它能让用户以近乎实时的方式来查看、分析海量的数据。Kibana 则是为 Elasticsearch 开发的前端 GUI,让用户可以很方便的以图形化的接口查询 Elasticsearch 中存储的数据,同时也提供了各种分析的模块,比如构建 dashboard 的功能。
我个人认为将 ELK 中的 L 理解成 Logging Agent 更合适。Elasticsearch 和 Kibana 基本就是存储、检索和分析 log 的标准方案,而 Logstash 则并不是唯一的收集 log 的方案,Fluentd 和 Filebeats 也能用于收集 log。所以现在网上有 ELK,EFK 之类的缩写。
一般采用的架构如下图所示。通常一个小型的 cluster 有三个节点,在这三个节点上可能会运行几十个甚至上百个容器。而我们只需要在每个节点上启动一个 logging agent 的实例(在 kubernetes 中就是 DaemonSet 的概念)即可。
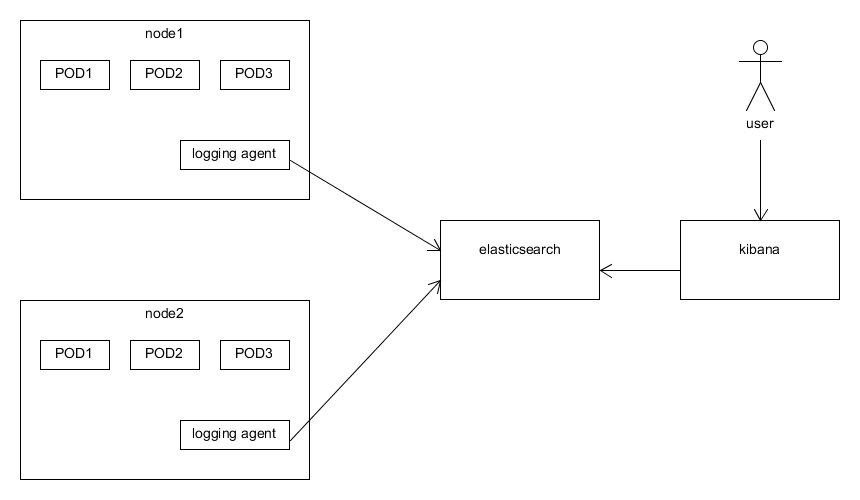
Filebeats、Logstash、Fluentd 三者的区别和联系
这里有必要对 Filebeats、Logstash 和 Fluentd 三者之间的联系和区别做一个简要的说明。Filebeats 是一个轻量级的收集本地 log 数据的方案,官方对 Filebeats 的说明如下。可以看出 Filebeats 功能比较单一,它仅仅只能收集本地的 log,但并不能对收集到的 Log 做什么处理,所以通常 Filebeats 通常需要将收集到的 log 发送到 Logstash 做进一步的处理。
Filebeat is a log data shipper for local files. Installed as an agent on your servers, Filebeat monitors the log directories or specific log files, tails the files, and forwards them either to Elasticsearch or Logstash for indexing
Logstash 和 Fluentd 都具有收集并处理 log 的能力,网上有很多关于二者的对比,提供一个写得比较好的文章链接如下。功能上二者旗鼓相当,但 Logstash 消耗更多的 memory,对此 Logstash 的解决方案是使用 Filebeats 从各个叶子节点上收集 log,当然 Fluentd 也有对应的 Fluent Bit。
https://logz.io/blog/fluentd-Logstash/
另外一个重要的区别是 Fluentd 抽象性做得更好,对用户屏蔽了底层细节的繁琐。作者的原话如下:
Fluentd’s approach is more declarative whereas Logstash’s method is procedural. For programmers trained in procedural programming, Logstash’s configuration can be easier to get started. On the other hand, Fluentd’s tag-based routing allows complex routing to be expressed cleanly.
虽然作者说是要中立的对二者(Logstash 和 Fluentd)进行对比,但实际上偏向性很明显了:)。本文也主要基于 Fluentd 进行介绍,不过总体思路都是相通的。
额外说一点,Filebeats、Logstash、Elasticsearch 和 Kibana 是属于同一家公司的开源项目,官方文档如下:
https://www.elastic.co/guide/index.html
Fluentd 则是另一家公司的开源项目,官方文档如下:
关于 ELK
ELK 简介
ELK 是 Elastic 公司提供的一套完整的日志收集以及展示的解决方案,是三个产品的首字母缩写,分别是 Elasticsearch、Logstash 和 Kibana。

- Elasticsearch 是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能
- Logstash 是一个用来搜集、分析、过滤日志的工具
- Kibana 是一个基于 Web 的图形界面,用于搜索、分析和可视化存储在 Elasticsearch 指标中的日志数据
ELK 日志处理流程

上图展示了在 Docker 环境下,一个典型的 ELK 方案下的日志收集处理流程:
- Logstash 从各个 Docker 容器中提取日志信息
- Logstash 将日志转发到 Elasticsearch 进行索引和保存
- Kibana 负责分析和可视化日志信息
由于 Logstash 在数据收集上并不出色,而且作为 Agent,其性能并不达标。基于此,Elastic 发布了 beats 系列轻量级采集组件。
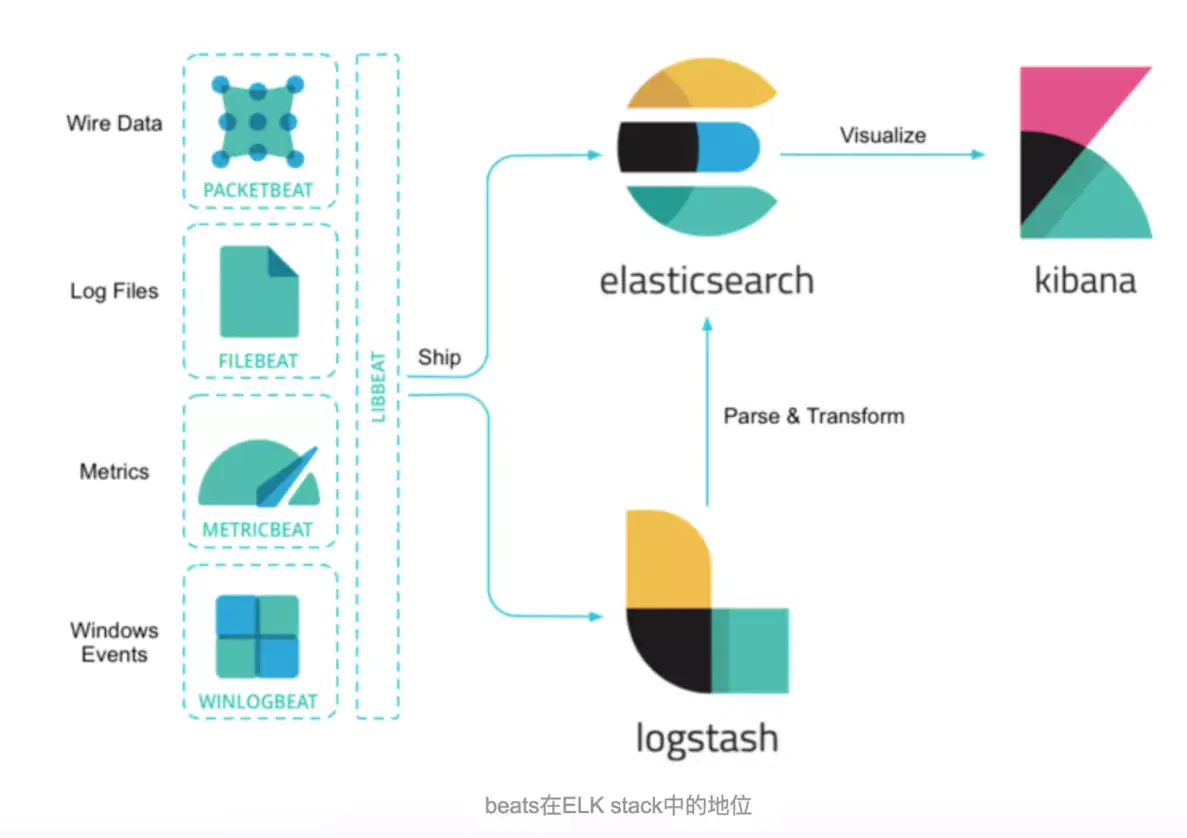
这里我们要实践的 Beat 组件是 Filebeat,Filebeat 是构建于 beats 之上的,应用于日志收集场景的实现,用来替代 Logstash Forwarder 的下一代 Logstash 收集器,是为了更快速稳定轻量低耗地进行收集工作,它可以很方便地与 Logstash 还有直接与 Elasticsearch 进行对接。
本次实验直接使用 Filebeat 作为 Agent,它会收集我们在第一篇《Docker logs & logging driver》中介绍的 json-file 的 log 文件中的记录变动,并直接将日志发给 Elasticsearch 进行索引和保存,其处理流程变为下图,你也可以认为它可以称作 EFK。

ELK 套件的安装
本次实验我们采用 Docker 方式部署一个最小规模的 ELK 运行环境,当然,实际环境中我们或许需要考虑高可用和负载均衡。
首先拉取一下 sebp/elk 这个集成镜像,这里选择的 tag 版本是 latest:
1 | docker pull sebp/elk:latest |
注:由于其包含了整个 ELK 方案,所以需要耐心等待一会。
通过以下命令使用 sebp/elk 这个集成镜像启动运行 ELK:
1 | docker run -it -d --name elk \ |
运行完成之后就可以先访问一下 http://192.168.4.31:5601 看看 Kibana 的效果:
当然,目前没有任何可以显示的 ES 的索引和数据,再访问一下 http://192.168.4.31:9200 看看 Elasticsearch 的 API 接口是否可用:
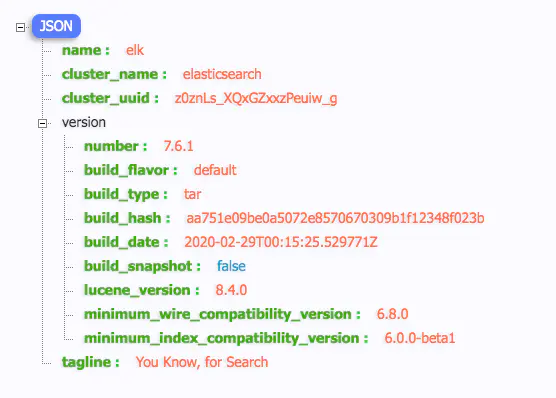
注意:
如果启动过程中发现一些错误,导致 ELK 容器无法启动,可以参考 《ElasticSearch 启动常见错误》 一文。如果你的主机内存低于 4G,建议增加配置设置 ES 内存使用大小,以免启动不了。例如下面增加的配置,限制 ES 内存使用最大为 1G:
1 | docker run -it -d --name elk \ |
若启动容器的时候提示 max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 请参考
1 | # 编辑 sysctl.con |
Filebeat 配置
安装 Filebeat
这里我们通过 rpm 的方式下载 Filebeat,注意这里下载和我们 ELK 对应的版本(ELK 是 7.6.1,这里也是下载 7.6.1,避免出现错误):
1 | wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.1-x86_64.rpm |
配置 Filebeat
这里我们需要告诉 Filebeat 要监控哪些日志文件 及 将日志发送到哪里去,因此我们需要修改一下 Filebeat 的配置:
1 | nano /etc/filebeat/filebeat.yml |
要修改的内容为:
(1)监控哪些日志?
1 | filebeat.inputs: |
这里指定 paths:/var/lib/docker/containers/*/*.log,另外需要注意的是将 enabled 设为 true。
(2)将日志发到哪里?
1 | #-------------------------- Elasticsearch output ------------------------------ |
这里指定直接发送到 Elasticsearch,配置一下 ES 的接口地址即可。
注意:如果要发到 Logstash,请使用后面这段配置,将其取消注释进行相关配置即可:
1 | #----------------------------- Logstash output -------------------------------- |
启动 Filebeat
由于 Filebeat 在安装时已经注册为 systemd 的服务,所以只需要直接启动即可:
1 | systemctl start filebeat |
设置开机启动:
1 | systemctl enable filebeat |
检查 Filebeat 启动状态:
1 | systemctl status filebeat |
上述操作总结为脚本为:
1 | wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.6.1-x86_64.rpm |
Kibana 配置
接下来我们就要告诉 Kibana,要查询和分析 Elasticsearch 中的哪些日志,因此需要配置一个 Index Pattern。从 Filebeat 中我们知道 Index 是 filebeat-timestamp 这种格式,因此这里我们定义 Index Pattern 为 filebeat-*
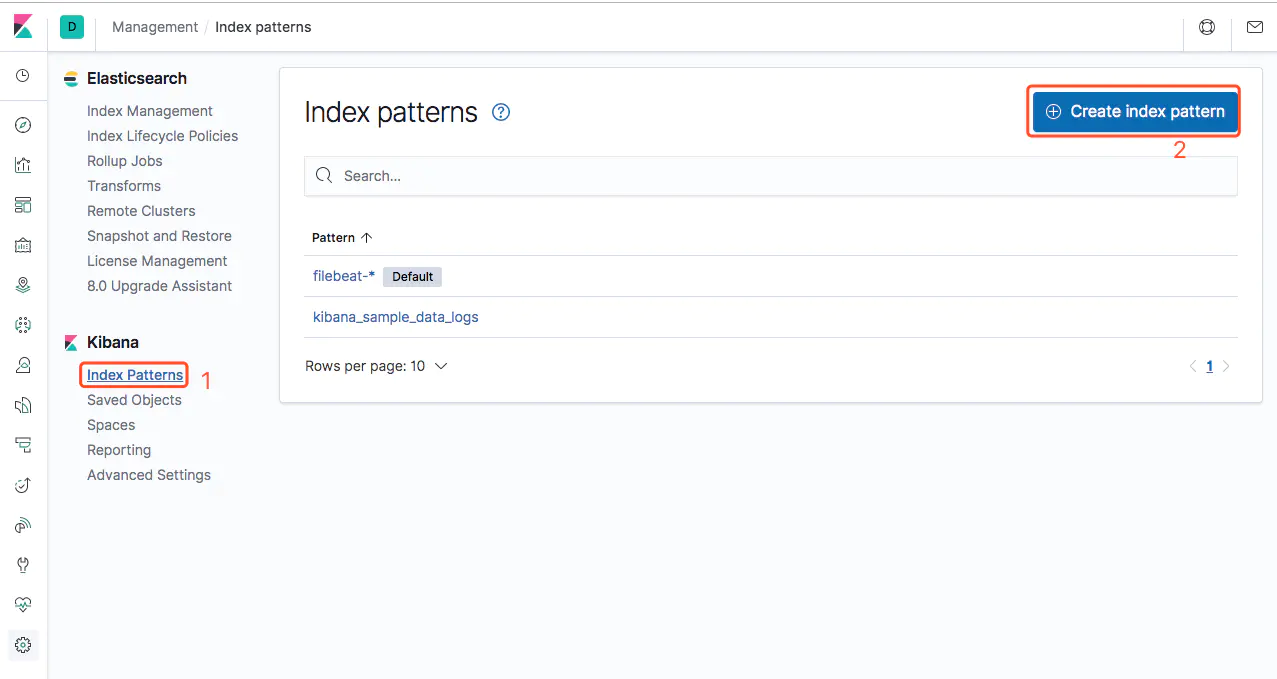
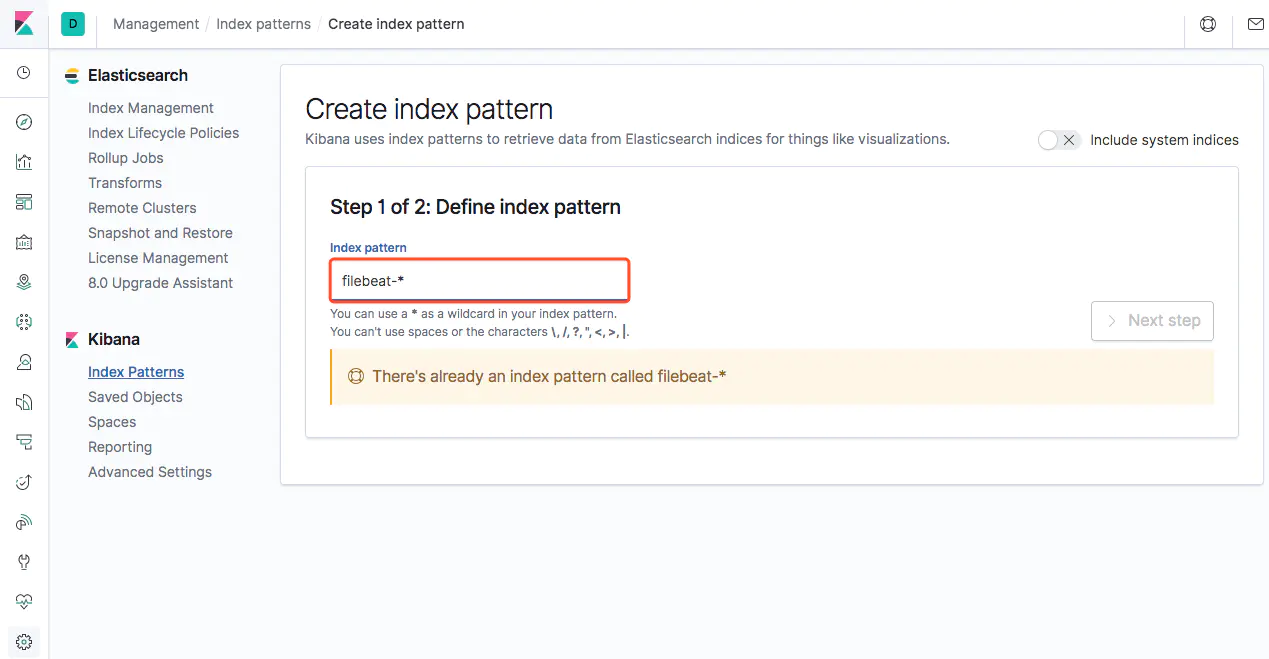
点击 Next Step,这里我们选择 Time Filter field name 为 @timestamp:
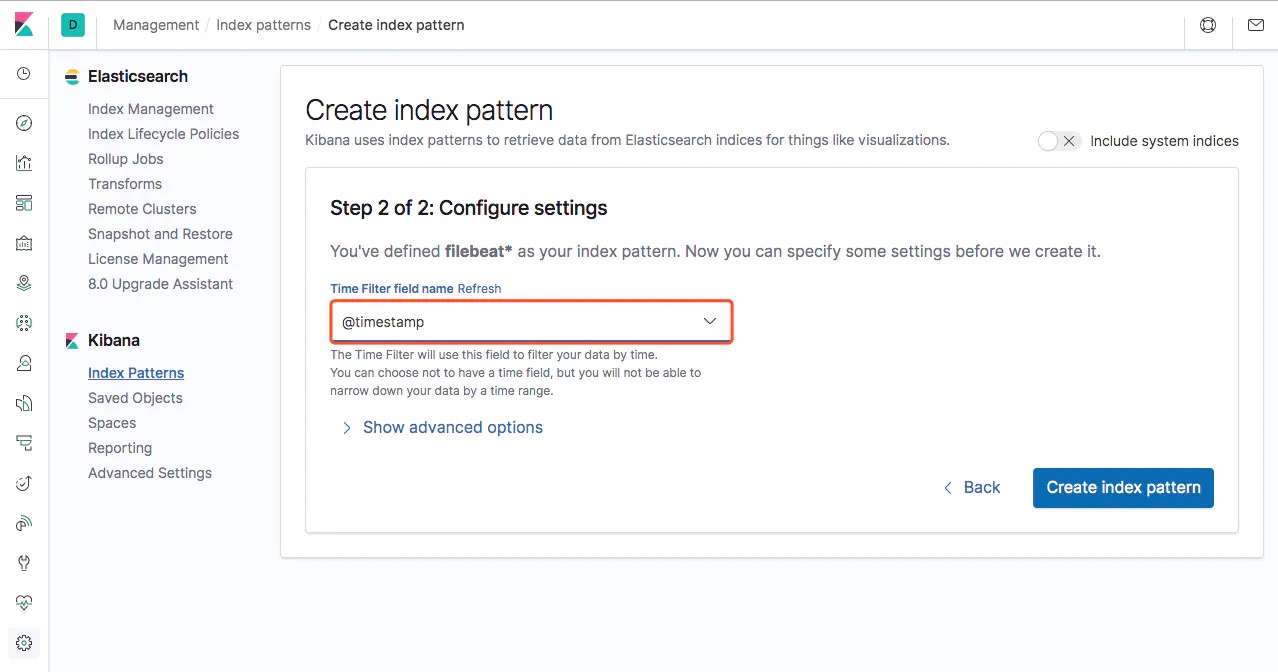
单击 Create index pattern 按钮,即可完成配置。
这时我们单击 Kibana 左侧的 Discover 菜单,即可看到容器的日志信息啦:
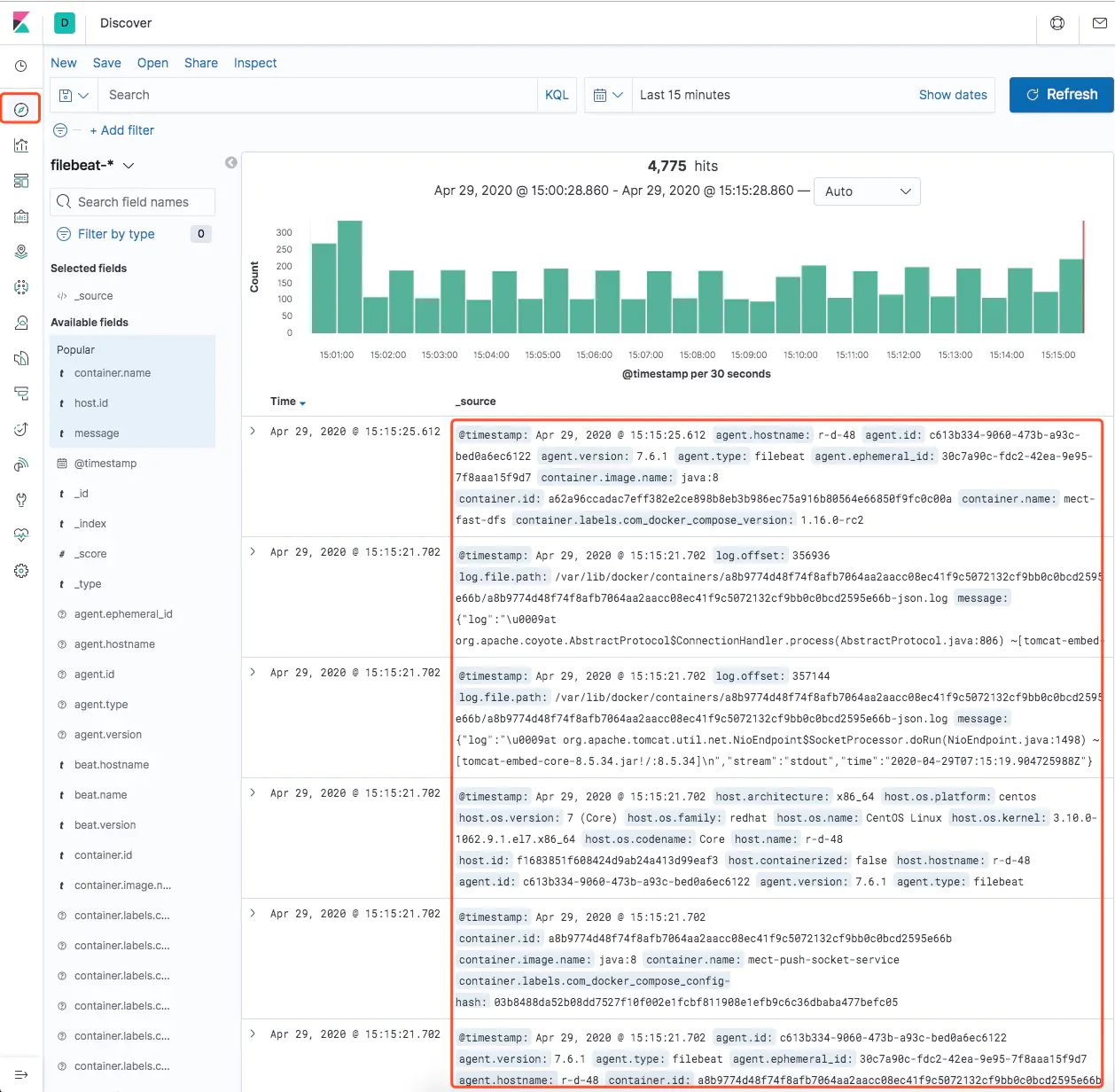
仔细看看细节,我们关注一下 message 字段:

可以看到,我们重点要关注的是 message,因此我们也可以筛选一下只看这个字段的信息:
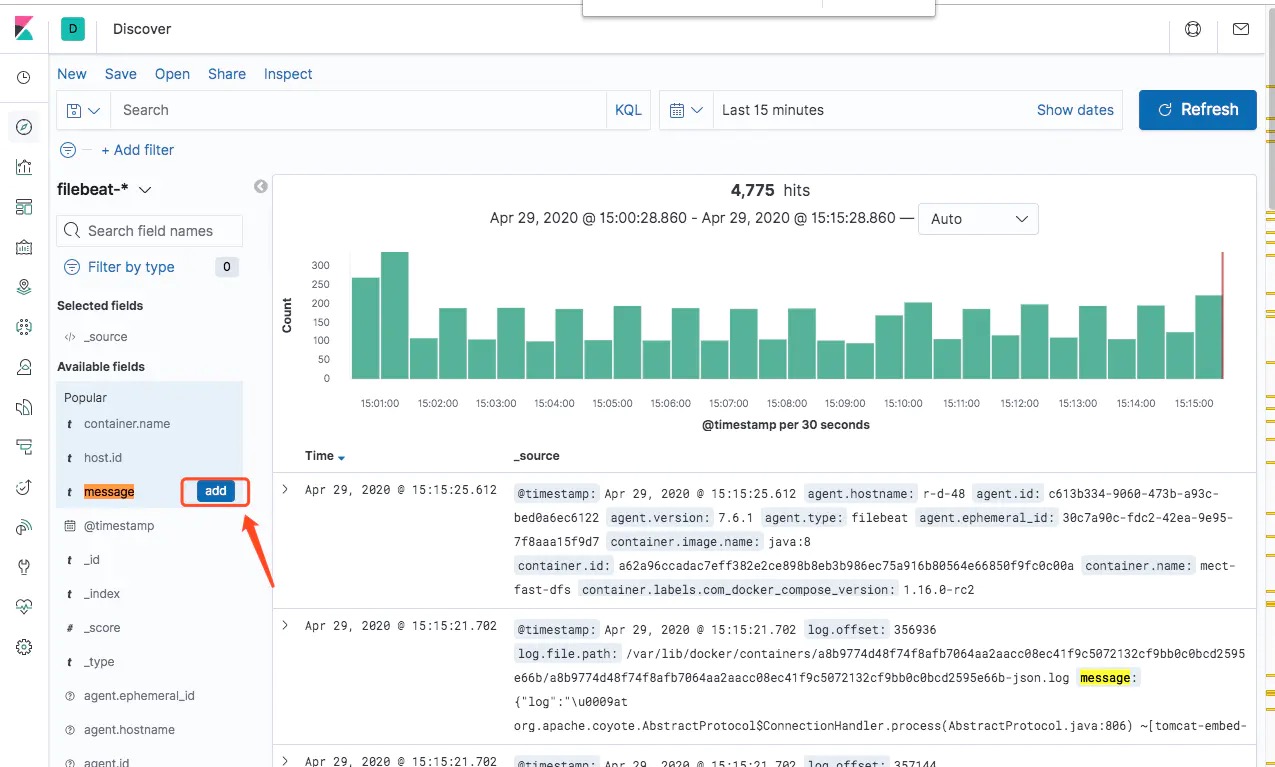
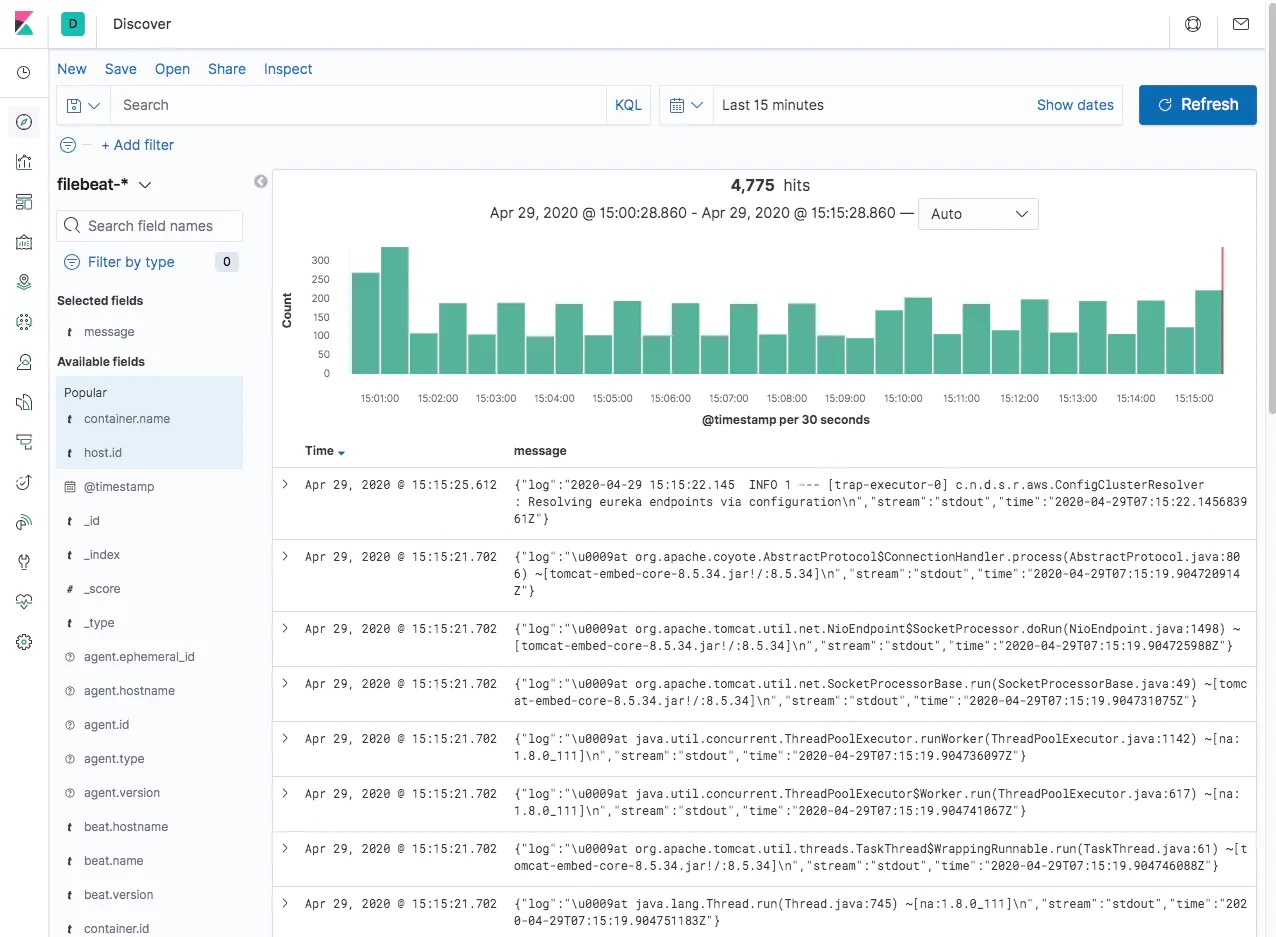
这里只是朴素的展示了导入 ELK 的日志信息,实际上 ELK 还有很多很丰富的玩法,例如分析聚合、炫酷 Dashboard 等等。笔者在这里也是初步使用,就介绍到这里啦。
Fluentd 引入
关于 Fluentd
前面我们采用的是 Filebeat 收集 Docker 的日志信息,基于 Docker 默认的 json-file 这个 logging driver,这里我们改用 Fluentd 这个开源项目来替换 json-file 收集容器的日志。
Fluentd 是一个开源的数据收集器,专为处理数据流设计,使用 JSON 作为数据格式。它采用了插件式的架构,具有高可扩展性高可用性,同时还实现了高可靠的信息转发。Fluentd 也是云原生基金会 (CNCF) 的成员项目之一,遵循 Apache 2 License 协议,其 GitHub 地址为:https://github.com/fluent/fluentd/。Fluentd 与 Logstash 相比,比占用内存更少、社区更活跃,两者的对比可以参考这篇文章《Fluentd vs Logstash》。
因此,整个日志收集与处理流程变为下图,我们用 Filebeat 将 Fluentd 收集到的日志转发给 Elasticsearch。
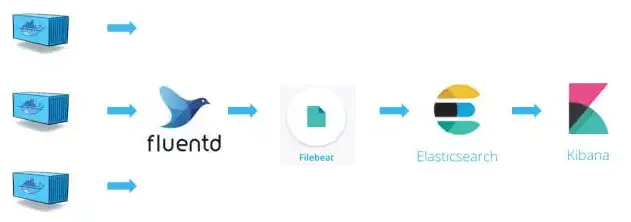
当然,我们也可以使用 Fluentd 的插件(fluent-plugin-elasticsearch)直接将日志发送给 Elasticsearch,可以根据自己的需要替换掉 Filebeat,从而形成 Fluentd => Elasticsearch => Kibana 的架构,也称作 EFK。
运行 Fluentd
这里我们通过容器来运行一个 Fluentd 采集器:
1 | docker run -it -d --name fluentd \ |
默认 Fluentd 会使用 24224 端口,其日志会收集在我们映射的路径下。
此外,我们还需要修改 Filebeat 的配置文件,将 / etc/fluentd/log 加入监控目录下:
1 | #=========================== Filebeat inputs ============================= |
添加监控配置之后,需要重新 restart 一下 filebeat:
1 | systemctl restart filebeat |
运行测试容器
为了验证效果,这里我们 Run 两个容器,并分别制定其 log-dirver 为 fluentd:
1 | docker run -d \ |
这里通过指定容器的 log-driver,以及为每个容器设立了 tag,方便我们后面验证查看日志。
验证 EFK 效果
这时再次进入 Kibana 中查看日志信息,便可以通过刚刚设置的 tag 信息筛选到刚刚添加的容器的日志信息了:
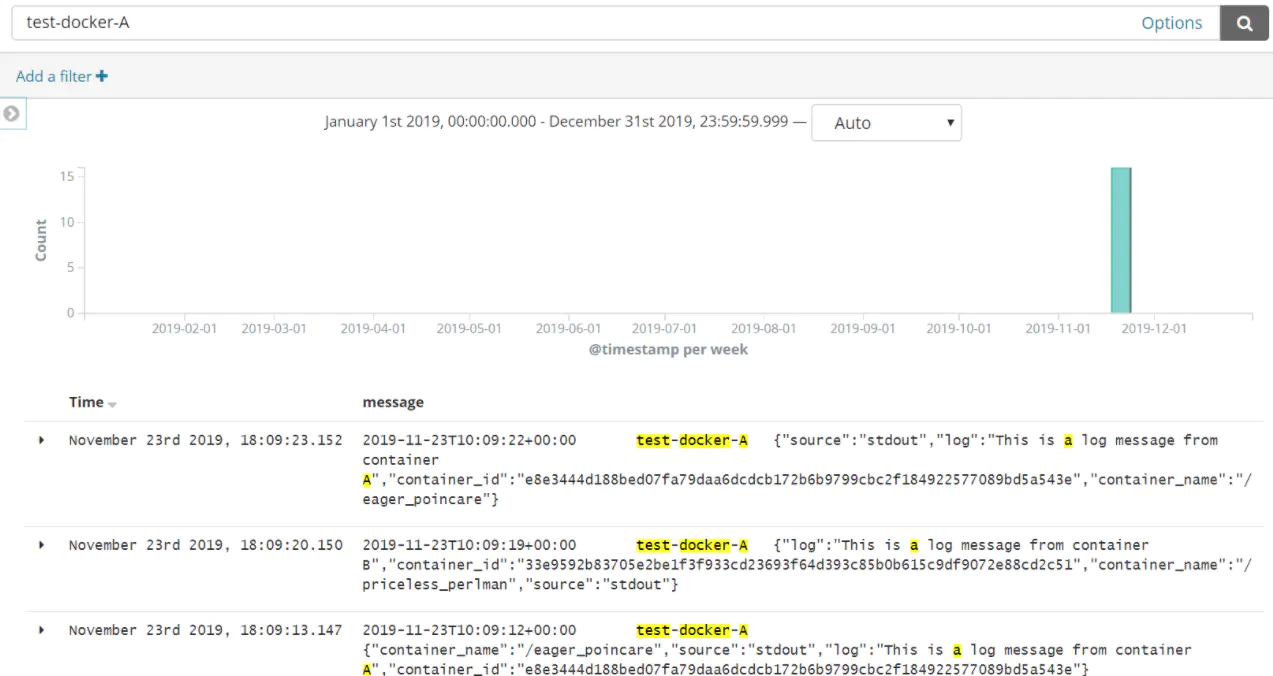
模拟日志生成压力测试工具
小结
本文从 ELK 的基本组成入手,介绍了 ELK 的基本处理流程,以及从 0 开始搭建了一个 ELK 环境,演示了基于 Filebeat 收集容器日志信息的案例。然后,通过引入 Fluentd 这个开源数据收集器,演示了如何基于 EFK 的日志收集案例。当然,ELK/EFK 有很多的知识点,笔者也还只是初步使用,希望未来能够分享更多的实践总结。
参考文章
本文转载自:「HelloDog」,原文:https://wsgzao.github.io/post/efk/,版权归原作者所有。欢迎投稿,投稿邮箱: editor@hi-linux.com。