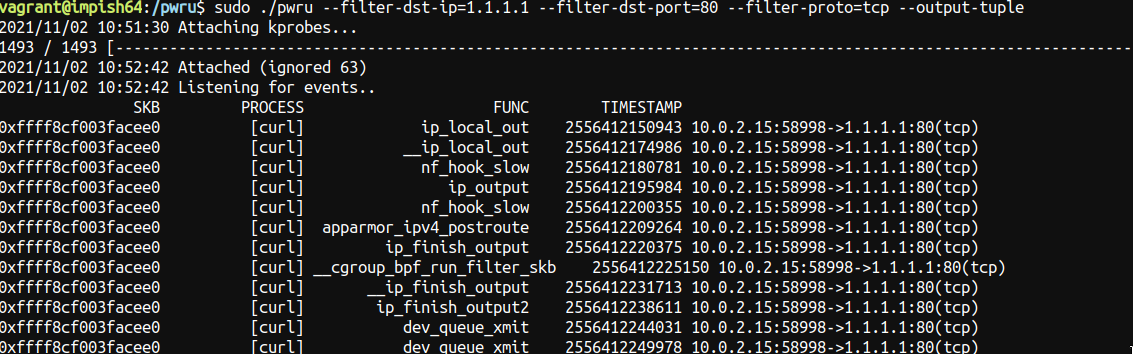
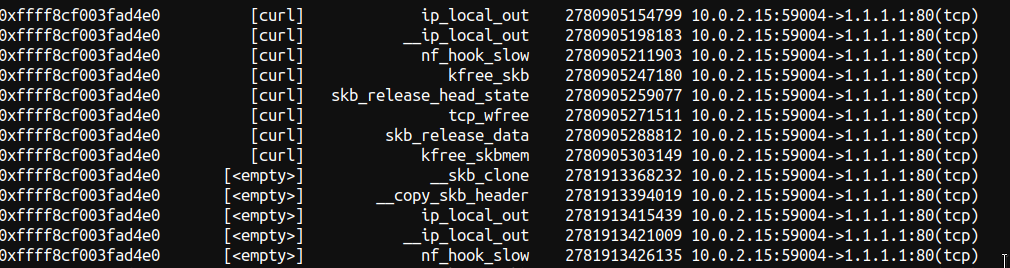
Usage of ./pwru: --filter-dst-ip string filter destination IP addr --filter-dst-port uint16 filter destination port --filter-func string filter kernel functions to be probed by name (exact match, supports RE2 regular expression) --filter-mark uint32 filter skb mark --filter-netns uint32 filter netns inode --filter-proto string filter L4 protocol (tcp, udp, icmp) --filter-src-ip string filter source IP addr --filter-src-port uint16 filter source port --output-limit-lines uint exit the program after the number of events has been received/printed --output-meta print skb metadata --output-relative-timestamp print relative timestamp per skb --output-skb print skb --output-stack print stack --output-tuple print L4 tuple
int nf_hook_slow(struct sk_buff *skb, struct nf_hook_state *state, const struct nf_hook_entries *e, unsigned int s) { unsigned int verdict; int ret;
for (; s < e->num_hook_entries; s++) { verdict = nf_hook_entry_hookfn(&e->hooks[s], skb, state); switch (verdict & NF_VERDICT_MASK) { case NF_ACCEPT: break; case NF_DROP: kfree_skb(skb); ret = NF_DROP_GETERR(verdict); if (ret == 0) ret = -EPERM; return ret; case NF_QUEUE: ret = nf_queue(skb, state, s, verdict); if (ret == 1) continue; return ret; default: /* Implicit handling for NF_STOLEN, as well as any other * non conventional verdicts. */ return 0; } }
//TODO: if there are more options later, then you can consider using a bit map OutputRelativeTS uint8 OutputMeta uint8 OutputTuple uint8 OutputSkb uint8 OutputStack uint8