偶然看到一篇 Cloudflare 的博客 How to drop 10 million packets per second,如何实现单核情况下一秒钟丢弃 1000 万个数据包,原文循序渐进,从最简单的用户态丢弃到使用非常新的技术 XDP,逐步将单核丢包性能提升到 10 mpps,很有意思,网上也没有看到原文的中文版本,所以这里顺便翻译一下,看看 Cloudflare 是如何处理类似的情况的。
在公司内部,我们的抗 DDoS 团队有时会被人们称作 “数据包丢弃者”。当其他团队为流经我们网络的流量做了很多令人兴奋的聪明玩意时,我们也很享受探索如何丢弃这些流量的新方法。
能以最快速度丢掉网络包,对于抵抗 DDoS 攻击来说,是非常重要的。丢掉发送到我们服务器的数据包,和听上去一样简单,可以在很多层面上进行。每个技术都有他的优点和缺陷,在这篇 Blog 里,我们会一起看一下我们到目前为止用到的技术。
试验台
为了说明方法的相对性能,我们将通过一些基准测试,这些测试是设计好的,可以得到一系列的数据。我们使用了一台 Intel 的服务器,这台机器有一块 10Gbps 网卡,机器的其他配置信息其实并不是很重要,因为这些测试的目标是为了显示出操作系统而不是硬件层面的限制。
我们的测试设置如下:
-
我们传输大量小的 UDP 数据包,达到 14Mpps(每秒数百万个数据包)。
-
此流量指向目标服务器上的单个 CPU。
-
我们测量内核在该 CPU 上处理的数据包数量。
我们并没有尝试优化用户空间应用程序的速度,也没有尝试提升数据吞吐量 - 相反,我们尝试专门展示内核层的瓶颈。
生成的流量可以对 conntrack 施加最大压力 - 数据包使用随机源IP和端口字段。 tcpdump 的结果如下:
1 | $ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234 |
在目标机器,我们将所有的流量都定向到网卡同一个 RX 队列上,也就是说所有的数据都只会被一个 CPU 核处理。我们通过硬件流转向实现这一目标:
1 | ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2 |
基准测试通常也很困难,当我们在准备测试的过程中,我们发现如果系统中有活动的 raw socket 也会影响性能,事后看很明显,但是也很容易忽略类似的问题。所以在测试之前需要确认没有任何 tcpdump 进程在运行,可以通过下面的方式查看:
1 | $ ss -A raw,packet_raw -l -p|cat |
最后,我们要关闭 Intel Turbo Boost 特性:
1 | echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo |
虽然 Turbo Boost 很好,而且可以提升至少 20% 的吞吐量,但是也会极大的影响测试结果的标准差,在开启状态下偏大达到了 ±1.5%,而关闭之后偏差下降到了 0.25%。
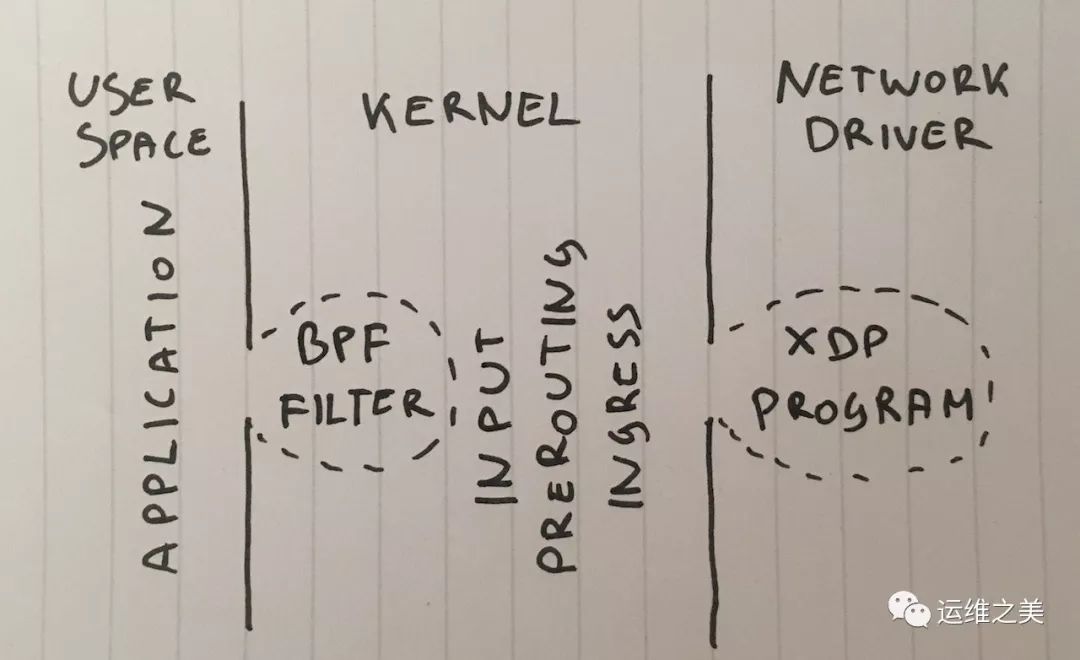
第一阶段 在应用程序中丢弃包
让我们从将数据包传递到应用程序并在用户空间代码中忽略它们的想法开始。 对于测试设置,首先需要确保 iptables 不会影响性能:
1 | iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT |
应用程序的代码就是一个简单的循环,获取数据,然后直接丢弃:
1 | s = socket.socket(AF_INET, SOCK_DGRAM) |
这里有准备好的 C 代码,运行结果:
1 | $ ./dropping-packets/recvmmsg-loop |
对于这个实现,我们利用 ethtool 和 mmwatch 工具可以实现从硬件队列中以 175kpps 的速度读取数据包。
硬件上看接收的速度是 14Mpps,但是针对单核处理的 RX 队列,这些数据包已经无法处理了。可以通过 mpstat 工具确认:
1 | $ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver' |
可以看到用户代码不是瓶颈,在 CPU #1 上有 27% sys + 2% userspace 的占用,但是 CPU #2 被网络软中断( SOFTIRQ )占用了 100%。
需要说明的是,使用 recvmmsg(2) 很重要,在 Spectre 漏洞被发现的现在,系统调用的成本变得更加高了,我们使用了 4.14 版本的内核,并开启了 KPTI 和 Retpoline:
1 | $ tail -n +1 /sys/devices/system/cpu/vulnerabilities/* |
第二阶段 干掉 conntrack
我们特别的设计了这个测试,用随机的原 IP 和端口,用来给 conntrack 层施加压力。这个可以通过查看 conntrack 数量的方式确认,在测试中,conntrack 数量达到最大:
1 | $ conntrack -C |
也能从 dmesg 中看到 conntrack 日志:
1 | [4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet |
为了加速我们的测试,把它关掉:
1 | iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK |
然后重新测试:
1 | $ ./dropping-packets/recvmmsg-loop |
程序性能里面提升到了 333kpps,赞!
PS:通过
SO_BUSY_POLL选项,我们可以将性能提升到 470k pps,但是这个是另一个话题了。
第三阶段 利用 BPF 进行丢包操作
更进一步,为什么我们要在用户态进行丢包呢?虽然这个技术不常见,但是我们可以使用 setsockopt(SO_ATTACH_FILTER) 添加一个 cBPF 过滤器到一个 socket 上,让程序在内核态进行丢包操作。
这里是代码,运行一下:
1 | $ ./bpf-drop |
使用 BPF 进行丢弃操作( cBPF 和 eBPF 有相似的性能),我们大致达到了 512kpps 的性能。所有的包都在 BPF 过滤器中丢弃了,由于依然需要使用到软中断,所以只是省掉了唤醒用户态程序的 CPU 消耗。
第四阶段 使用 iptables 在路由阶段结束后丢弃
在下个阶段,我们可以简单的设置 iptables INPUT 规则来丢弃包:
1 | iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP |
需要注意的是我们之前已经通过 -j NOTRACK 关闭了 conntrack,这两条规则实现了 608kbps 的性能。
看下 iptables 的统计信息:
1 | $ mmwatch 'iptables -L -v -n -x | head' |
600kpps 不差了,但是我们能做到更好!
第五阶段 使用 iptables 在路由之前丢弃
有一个更快的方法,就是在包路由之前丢弃,可以通过下面的命令:
1 | iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP |
这个方法的性能高达 1.688 pps。
这是非常明显的性能提升,我并不是特别明白多了一次路由差距这么大,要么是我们的路由层非常的复杂,或者在服务器的配置上有 bug。
在任何情况下,通过 iptables 的 raw 表进行操作绝对是最快的方法。
第六阶段,使用 nftables 在 CONNTRACK 之前丢弃
iptables 在现在已经有点过时了,更新的玩意是 nftables,关于为什么 nftables 技术更优越,请参阅此视频。 由于许多原因,Nftables 承诺比老旧的 iptables 更快,其中有一个说法是 retpolines(没有间接跳跃的猜测)严重影响了 iptables 性能。
由于这篇文章不是关于比较nftables和iptables的速度,让我们尝试一下我能想到的最快的方法:
1 | nft add table netdev filter |
相关的统计信息可以通过这个命令查看:
1 | $ mmwatch 'nft --handle list chain netdev filter input' |
Nftables “ingress” Hook 性能卡在了 1.53 mpps。 这比 PREROUTING 层中的 iptables 稍慢。 这令人费解 - 理论上 ingress 在 PREROUTING 之前发生,所以应该更快。
在我们的测试中 nftables 比 iptables 略慢,但不是很多。 Nftables 仍然更好。
第七阶段 利用 tc 的 ingress 策略丢包
有个比较令人震惊的事实是 tc (traffic control) 的 ingress hook 发生在 PREROUTING 之前。tc 可以并且确实能做到根据一定的标准来选择并丢弃数据包,但是做法确实比较 hacky,所以建议利用这个脚本进行设置,我们需要的是一个稍微复杂点的匹配,参考下面的命令:
1 | tc qdisc add dev vlan100 ingress |
可以验证:
1 | $ mmwatch 'tc -s filter show dev vlan100 ingress' |
通过 tc 的 ingress hook 的 u32 匹配,可以让我们实现单核 1.8mpps 的丢包能力,这个很棒!
但是,我们可以更快一点…
第八阶段 XDP_DROP
最后,终极武器是 XDP - eXpress Data Path。通过 XDP,我们可以在网络驱动层运行 eBPF 代码。最重要的是,这个阶段发生在分配 skbuff 内存之前,可以获得超高的速度。
通常 XDP 项目包含两部分:
-
被加载到内核的 eBPB 代码
-
用户态的加载器,可以将代码加载到正确的网卡,并且控制他们
编写加载器很难,但是我们可以利用 iproute2 的这个新特性,用一个很简单的命令加载:
1 | ip link set dev ext0 xdp obj xdp-drop-ebpf.o |
搞定!
这个 eBPF 的代码在这里。这个程序解析IP数据包,然后寻找对应的特征:IP 传输、UDP 协议、对应的子网和端口
1 | if (h_proto == htons(ETH_P_IP)) { |
XDP 程序需要用现代的 clang 编译器编译成 BPF 字节码,完成之后可以加载并验证:
1 | $ ip link show dev ext0 |
然后通过 ethtool -S 查看网卡的统计信息:
1 | $ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"' |
利用 XDP ,我们实现了在单核上,每秒钟丢弃 1000 万个包!

总结
我们在 IPv4 和 IPv6 上重复了实验,并画了这张图:
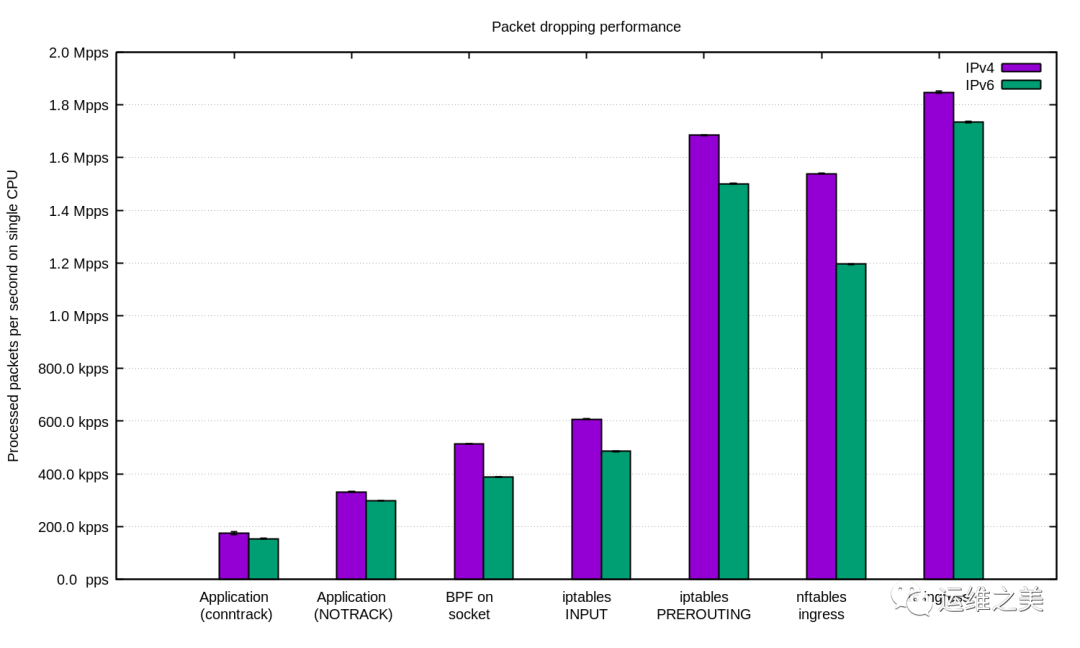
总的来说在我们现在的设置下,IPv6 比 IPv4 要稍微慢一些,需要注意的是 IPv6 的包也稍微大了一些,所以这性能上的区别还是可以理解的。
Linux 提供了很多过滤数据包的 Hook,每个都有不同的性能和易用性。
对于应对 DDoS 的场景,在用户态的应用程序里处理这些数据包是合理的,通过调整应用程序,也可以获得不错的性能。
而对于有随机源 IP 和端口的攻击,关闭 conntrack 的特性来获得性能提升也是值得的,但是 conntrack 在某些攻击情况下,还是很有用的。
针对其他情况下,利用 Linux 的防火墙来作为抗 DDoS 的一部分还是很有意义的,在这种情况下要尽量利用 -t raw PREROUTING 这一层,因为这一层比 filter 表要快很多。
对于要求更高的工作负载,我们还有 XDP,而且他很强大,下面是和上面相同的图表,但是加上了 XDP:
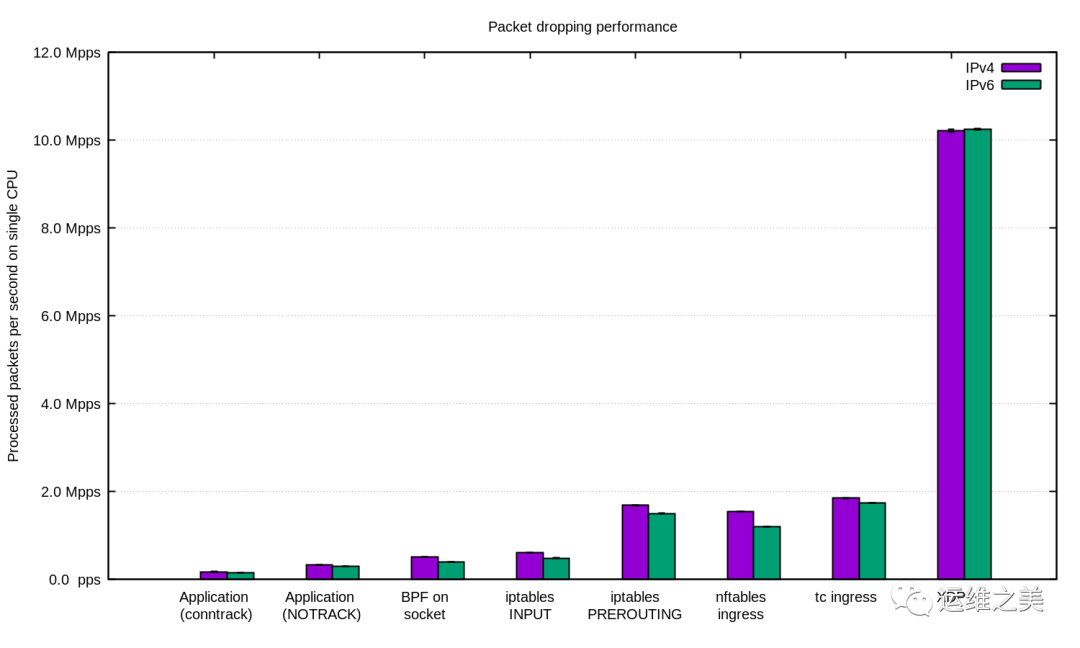
如果需要重现这些数据,可以看看项目代码的 README。
参考文档
-
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/recvmmsg-loop.c
-
https://blog.cloudflare.com/three-little-tools-mmsum-mmwatch-mmhistogram/
-
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/bpf-drop.c
-
https://github.com/netoptimizer/network-testing/blob/master/tc/tc_ingress_drop.sh
-
https://prototype-kernel.readthedocs.io/en/latest/networking/XDP/
-
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/xdp-drop-ebpf.c
-
https://github.com/cloudflare/cloudflare-blog/blob/master/2018-07-dropping-packets/README.md
本文转载自:「C0reFast 记事本」,原文:https://url.cn/58wrb9u,版权归原作者所有。欢迎投稿,投稿邮箱:
editor@hi-linux.com。